5P;1R Jellyfish Merkle Tree

This is a post in a series of articles I’m writing called “5 points & 1 resource” (think tl;dr but 5p;1r), where I summarize a list of 5 concepts that would have helped me start learning or re-learning a certain topic. It is intentionally far from a complete source of data.
Edit: Thank you to Aaron (one of the JMT authors) for reviewing this post.
An Addressable Merkle Tree (AMT) is a cryptographically authenticated deterministic data structure backed by a key-value store database used for account-based (non-UTXO-based) systems to map keys (i.e. addresses) to arbitrary binary data in each leaf node.
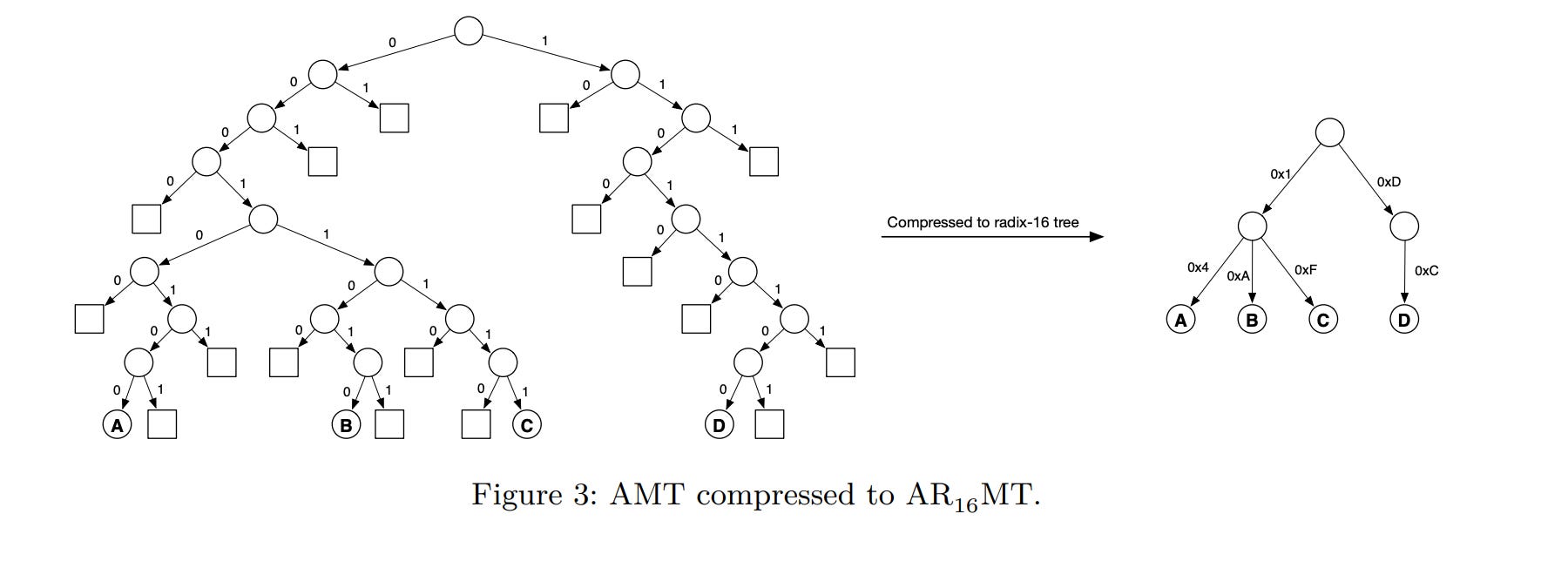
An Addressable Radix Merkle Tree (ARᵣMT) [Fig. 3] is a generalization of an AMT, a binary tree, where r > 2. With a key size of h bits, and each node having at most r children, the height of the tree is logᵣ(2ʰ). The tradeoffs of r are:
A large r is good for read-heavy applications but results in greater write amplification and higher storage costs when updating internal path nodes.
A small r is good for write-heavy applications, but results in higher I/O when querying or updating the tree.
A Sparse Merkle Tree (SMT) [Fig. 2] is an AMT which accounts for the fact that Perfect Merkle Trees are never needed for account-based models since most keys will not have data, thereby removing the need to store 2ʰ keys. The two main optimizations are:
Empty Subtrees are replaced with a constant default placeholder node value.
Single-Leaf Subtrees are replaced with one node reflecting the one leaf value.
A Jellyfish Merkle Tree (JMT) is a Sparse Addressable Radix Merkle Tree with r=16 (Sparse AR₁₆MT) that balances the tradeoff of storage, compute, read and write operations using two node types: Internal Node and Leaf (Data) Node. It optimizes for Log-Structured Merge-tree (LSM-tree) based key-value storage databases (e.g. RocksDB) by using Version-Based Node Keys whereby a monotonically increasing version number (i.e. # of transaction applied to the state) is prefixed to the node path in order to [Table 1]:
Enable version-based sharding
Automatically sort node updates written (i.e. appended) to disk in lexicographic order, reducing the disk bandwidth and IOPS of LSM-tree compaction.
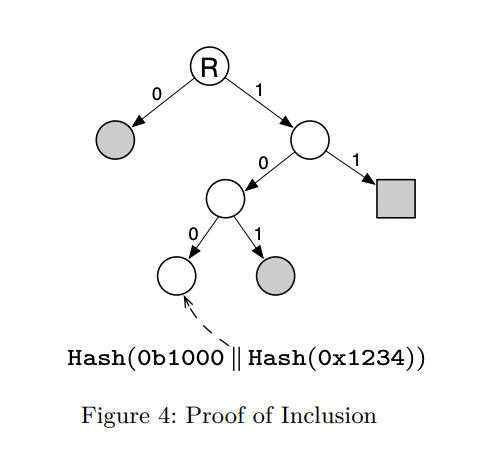
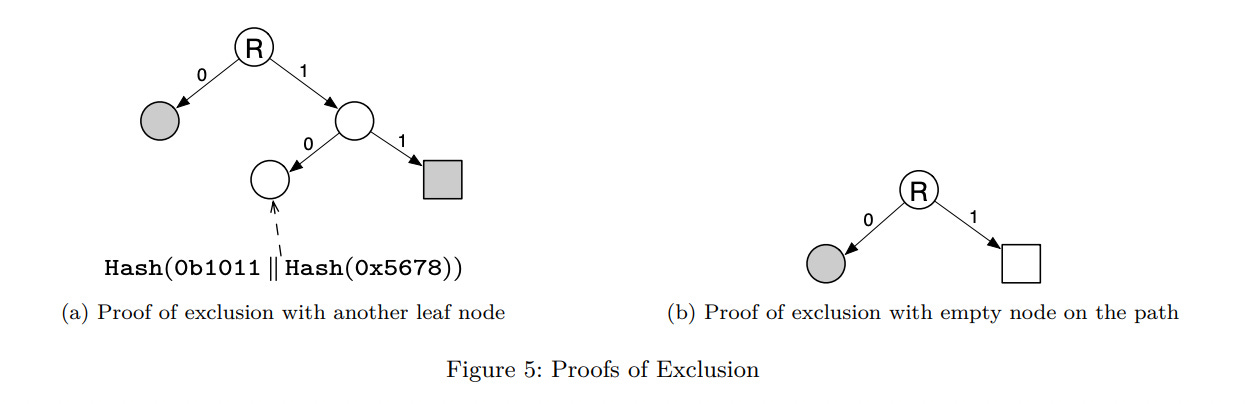
A JMT has an average Merkle Proof size of Θ(𝑙𝑜𝑔(num_existent_leaves)) and is split into three types [Fig. 4,5]:
Inclusion proof - A path to the node leaf with the appropriate key exists.
Exclusion proof (other node) - The leaf node in the path followed contains a key different from what’s expected.
Exclusion proof (empty node) - An empty (i.e. default placeholder) node exists along the path to the leaf node with the expected key.
There’s no better reference than the original white paper: Jellyfish Merkle Tree, but personally, I’d use my annotated version of the available at bafybeid5cdhsbqskrwwn5m2q7md5g2ldt6hihvzrt26ty6jbxqnza4gaie or s3.olshansky.info/JellyfishMerkleTreeWhitepaperReview.pdf.