
Annotated Presentation: "Relay Mining: Cryptographically Incentivizing Non-Validating Nodes"
EthCC 7

Inspired by Simon Willison’s How I make annotated Presentations, I figured I’d annotate a presentation I did at ethcc.io in July 2024. He says it best:
Even with that quality of presentation, I don’t think a video on its own is enough. My most recent talk was 40 minutes long—I’d love people to watch it, but I myself watch very few 40m long YouTube videos each year
I might also create a Twitter thread similar to what @_tessr did for her talk on optimism if anyone requests it.
The full video from EthCC is available here.
I got my first ETH in 2016 and had to use Mist to sync a full node so I could actually make use of the network. I don’t remember what I did with it, but I do remember infura.io coming out around Devcon 2. I managed to dig up the original video from their first announcement.
Since 2016, web3 infrastructure and RPC providers have become such a large commoditized industry since then that synching full nodes doesn’t even cross anyone’s mind anymore unless it’s their full-time job.
Relay Mining is a primitive that takes RPC provider infrastructure on-chain by creating real, verifiable, cryptographic incentives to provide services for any open source services or data sources.

I’d argue that understanding the problem is equally, or more, important than the technical details of how we solve it.
In the same way that newcomers to Bitcoin and crypto require a mindset shift, how RPC incentivization fits on-chain requires a mindset shift as well.
Joke: The “Technical Deep Dive” is the time to snooze or look at your phone ;)

Okay, so what were blockchains built for in the first place?

Secure state transitions! Writes!
The Ethereum whitepaper discusses how Ethereum and Bitcoin are state transition systems that solve the State Machine Replication. Everything related to measuring the performance of a blockchain is about enabling this as quickly and cheaply as possible without sacrificing liveness & safety.
However, any Web3 application (e.g. a wallet) often needs to read data. The number of reads is much greater than the number of writes.
I made another joke about how I spent 15 minutes talking to ChatGPT on how to anthropomorphize a network request. The crowd did not find it funny 😅
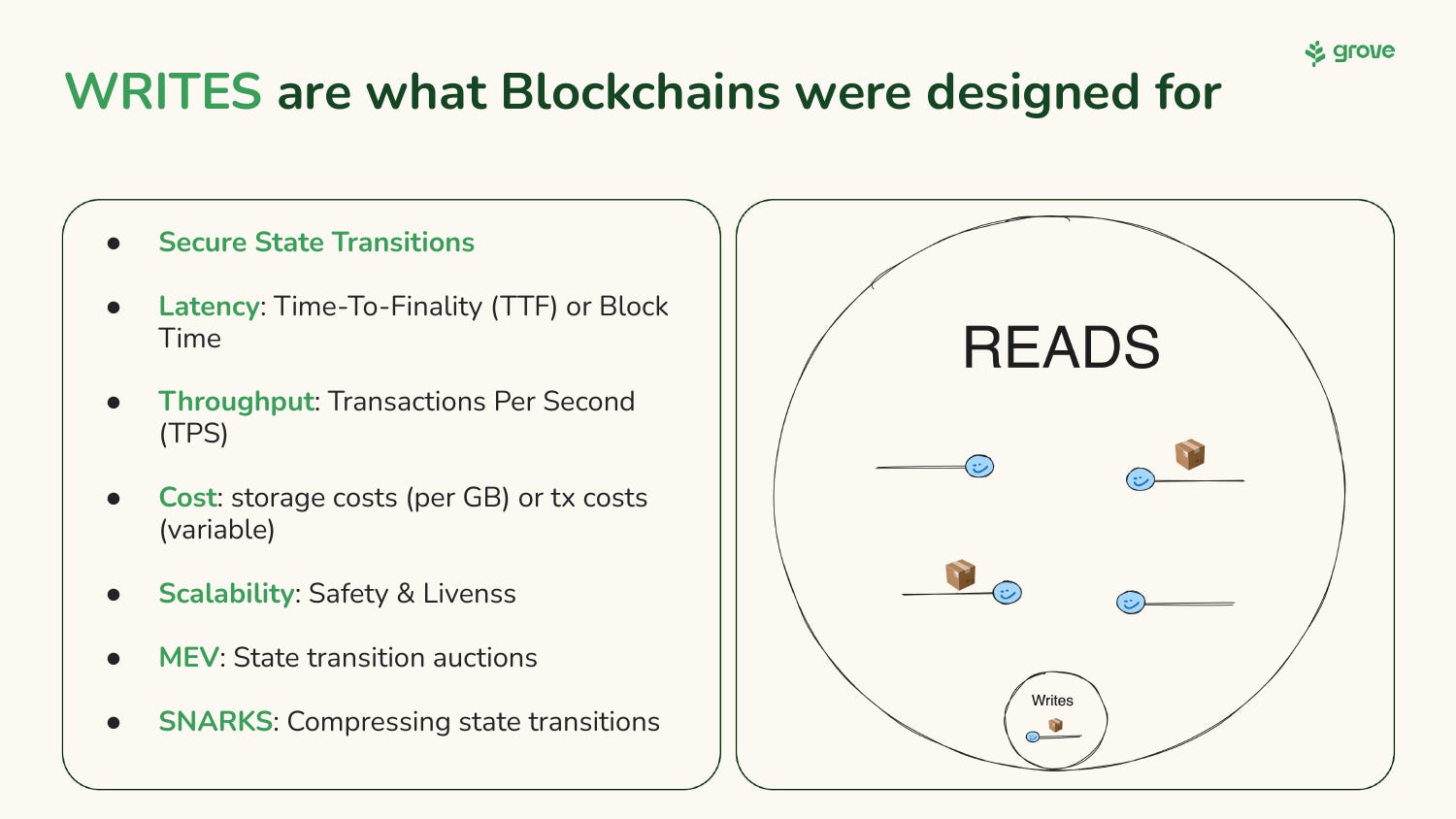
RPC Nodes were meant for reads!
This is much closer to traditional Web2 companies that provide a service via an API. All of the companies listed in the image I copy-pasted are the ones that actually enable web3 applications in production.
Fun fact: As Infura started decentralizing, it became one of our customers at Grove and I got to meet a lot of their team almost 7 years after first trying out the product. I love how small this world is.
To compare blockchains, the best dashboard I’ve found is Chainspect.
To compare RPC providers, the best dashboard I’ve found is atlas.1kx.capital. This literally came out a week before my presentation. I had to mix & match a few different websites prior, and was grateful how clean and simple this one is. Thanks 1kx!
I made another joke that if blockchains are like growing potatoes, than RPC providers is like servicing fries. It’s because RPC providers serve network requests. Get it? Related and dependent but different. 🥔 → 🍟

Finally, the answer to the first question!
Blockchains provide an incentive for storing/writing data but not reading it. Fundamentally, this means that we’re using blockchain primitives to build a different type of utility (i.e. an application) outside of what they are fundamentally designed for.

I’ve been to multiple conferences where blockchain researchers mention and discuss the problems around decentralizing RPC providers and Gateways, but it’s never their core focus. Like I said earlier, it’s related and important, but a bit orthogonal.
Moxie, the founder of Signal, identified this exact problem almost three years ago. The missing piece to the puzzle is incentive alignment.
Fun fact: the first podcast Moxie ever did was with Joe Rogan. Timestamped link for reference.

A lot of conversations around blockchains devolve to the need of being 100% permissionless, private, censorship-resistant, etc but it’s almost never the case.
This idealism is not feasible in practice, and I wanted to emphasize that Relay Mining also comes with tradeoffs, while still being a big step in the right direction. I really do hope other projects will adopt it.

Everything is about balance and tradeoffs. Doing deep analytical evaluations helps, but lots of decisions often come from intuition and experience.
One of the reasons why senior leadership is difficult is because it involves judging and navigating situations. Understanding which tradeoffs should be made at which point in time will have a lot of downstream effects. This is where having both deep and diverse experience can help, regardless of how knowledgeable someone is.
pokt.network has been on MainNet for almost 4 years, has handled more than 779B requests and handles about 600M requests a day. Over the years, we’ve heard the same issues, ideas, concerns and strategies dozens of times, enabling us to understand which tradeoffs should be made and why to provide user value. I highly recommend checking out poktscan.com to see the numbers yourself.

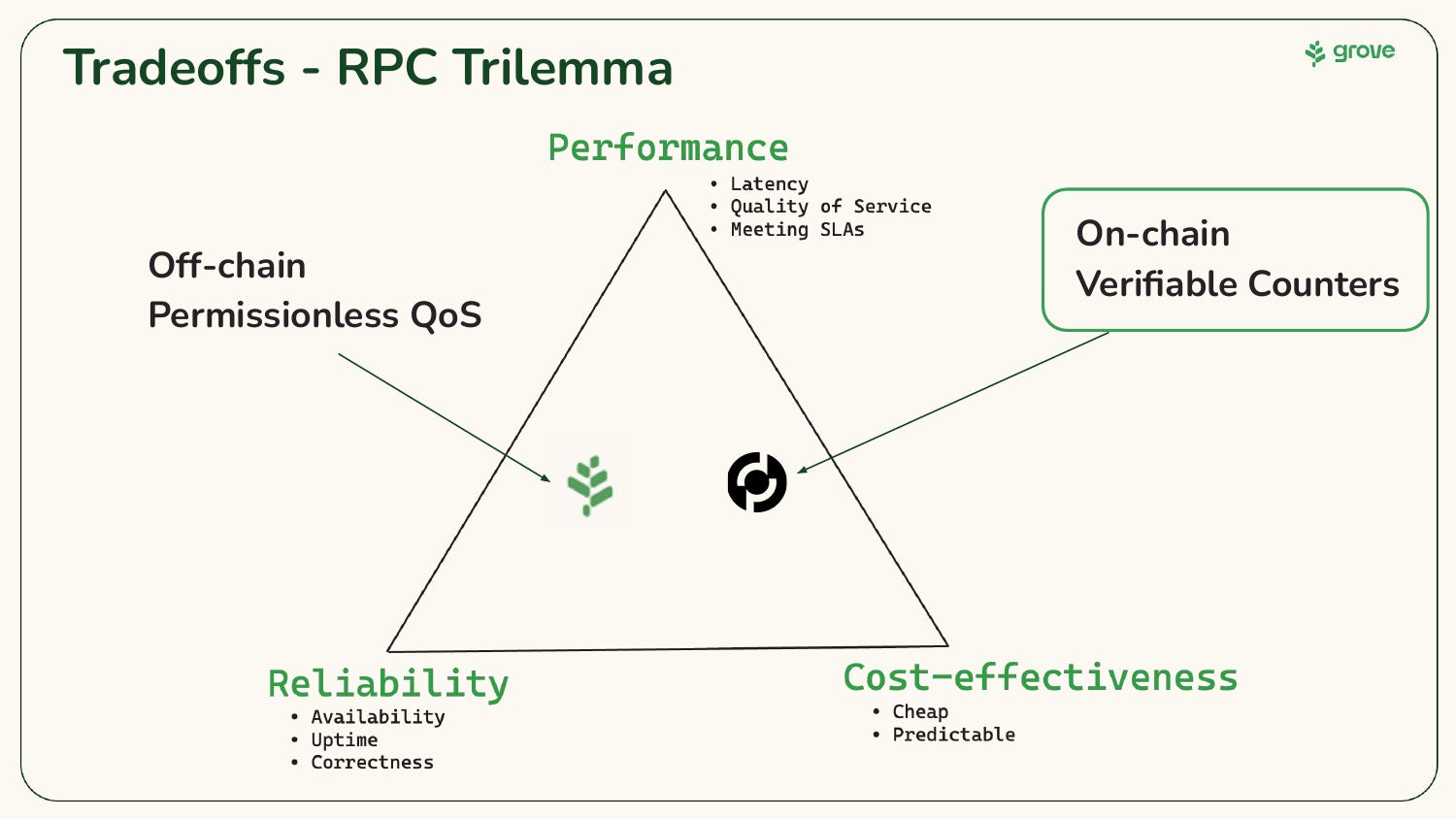
I always make sure to add a slide on the RPC Trilemma in any presentation I do. The fact that Reliability, Performance and Cost fit so well into the Remote Procedure Call (RPC) acronym is a gift.
A key distinction to understand is that there is a delineation of responsibilities between the network of suppliers, providing services, and the gateways, providing quality of service. In essence:
Supplier networks (i.e. POKT Network) provide services (e.g. access to open data sources) and are incentivized to provide a high quality-of-service through an on-chain verifiable counter.
Gateways (i.e. Grove) provide off-chain permissionless quality-of-service and are incentivized through off-chain business deals.
In the world of Web3, we tend to get wrapped up in the fact that decentralization is the goal. It is not!
Decentralization is a byproduct of a permissionless & incentivized system. If we have a supplier network with an N-of-1 or a supplier network with an N-of-1,000,000, both are fine as long as the end user gets a good service. As long as the network is permissionless and incentivized, the supplier network will scale as the needs of end users vary.
Quality and cost are what 99% of customers care about even though 99% of conversations revolve around how permissionless, censorship-resistant, etc a network is; 99% is just an empirical estimation.

We’ve almost arrived at the deep dive stage, but first, actor topology!

A lot is going on in the Actor overview. Here’s what we need to focus on:
Applications: The source of RPC requests.
Suppliers: The source of RPC responses.
Gateways: Optional “proxies” with value-add services that can be used or bypassed by Applications.
In this context, all of the following mean the same thing: L1, Blockchain, Data Availability Layer, Distributed Ledger or Settlement Layer.

A simplified version of the diagram above captures:
On-chain actors: These are records stored on-chain for the Application, Gateway & Supplier.
Off-chain actors: These are web services running off-chain to supplement the on-chain actors.
Relay Miner: An off-chain sidecar or coprocessor responsible for accounting of useful work (i.e. servicing RPC requests). This is where the magic happens, hence the magic school bus.

Finally, the moment we’ve all been waiting for. Relay Mining!
It’s similar to Bitcoin in the sense that miners continue mining until they find a hash that meets the necessary block difficulty and get paid for it. Similarly, POKT Network suppliers continue servicing requests until they find a Relay (i.e. a request/response pair) that meets the necessary difficulty (i.e. a golden payable relay).
The key difference between Relay Mining and Bitcoin Mining is that regardless of whether a Relay is payable or not, it still provides useful work to the end user, whereas the majority of Bitcoin mining is only there to preserve the security of the network, which is the source of the “wasted energy” debates; let’s not get into discussion here.
Whenever I need to give a fancy technical tl;dr of what Relay Mining is, I usually provide the following mouthful: it’s a dynamically scalable non-interactive probabilistic fraud-proof.

Relay Mining is a new primitive.
Similar to how the original Bitcoin Whitepaper proposes a Timestamp Server as the solution, we propose a Verifiable Counter, which has various downstream applications and implications.

There are two main steps to Relay Mining:
Tree Building: An off-chain process happening through a session to keep track of the amount of useful work (i.e. servicing RPC requests) done.
Claim & Proof lifecycle: A non-interactive on-chain commit-and-reveal scheme that ends with debiting and reward the Application and Supplier respectively.
There’s nothing fancy (i.e. no SNARKS, no ZK) going on here, but we are introducing a few novel proprietary design mechanisms:
Adding a committed Sum to Sparse Merkle Tries
Introducing the Closest Merkle Proof mechanic
Using Ring Signatures (popularized by Monero) for delegation, but not covered in this presentation

Step 1: A session pairs an Application and a list of Suppliers for a specific amount of time.
Throughout a session, a Supplier has the opportunity, but not the obligation, to service requests from an Application.
An Application does not have to send requests to a Supplier if it doesn’t want to or deems the Supplier faulty, adversarial or low quality. Similarly, a Supplier doesn’t have to respond to any of the requests from the Application. However, if both parties do not coordinate, the Application won’t get value from the service and the Supplier will have fewer opportunities to do work that’ll earn rewards (i.e. golden payable relays).
This mechanics creates an implicit incentive that is optimistic and opportunistic.

Step 2: A supplier finds golden payable relays.
Recall that a relay is a (request, response) pair that meets certain difficulty (i.e. target hash) criteria. The request is signed by the Application. The response is signed by the Supplier. The signatures and payloads are put into a structure and hashed to determine whether the relay is golden or not.
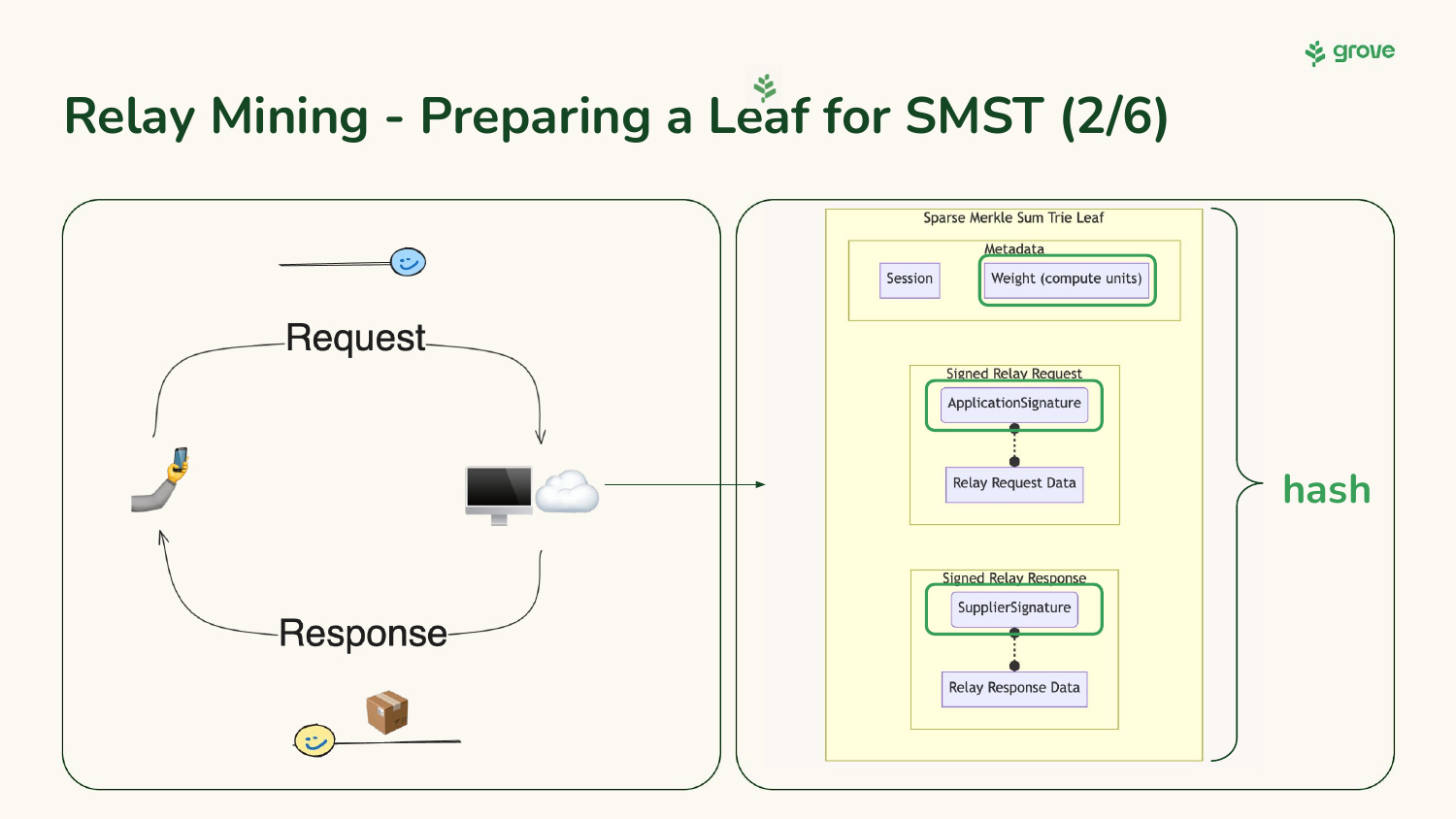
Step 3: Tree insertion.
Assuming the difficulty (i.e. target hash) is reached, the structure above is inserted as a leaf into the Sparse Merkle Sum Trie.

Step 4: Difficulty Modulation.
A core issue in the current (i.e. Morse) version of POKT Network is scalability. At the moment, all relays are inserted into a tree where the leaves are sorted. Aside from the fact that the leaves should never be sorted, this has scalability implications if we ever want to get to web2 scale where each Relay Miner coprocessor is handling 100s of millions of requests per session.
In the future version of POKT Network (i.e. Shannon, a complete rewrite), this is solved by having every on-chain service maintain an on-chain difficulty that modules as a result of the estimated service traffic.
# of relays sent » # of relays serviced » # of payable relays » # of relays verified

Step 5: Claim & Proof lifecycle.
The short story is that there’s a non-interactive on-chain commit-and-reveal mechanism at the end of every session for every (Application, Supplier, Service) group. The long story is that this is where all the validation and accounting settlement takes place. This is critical with lots of details but not very fun to dive into during a talk.

Step 6: Closest Merkle Proofs
In a Sparse Merkle Trie, most of the nodes and branches are empty. This is one of the key optimizations from the Jellyfish Merkle Tree whitepaper to enable performance and scalability. This creates an issue when the on-chain entropy requires proving a branch that does not have a populated leaf. In order to account for this, we have devised a mechanism that requires proof an non-deterministic populated closest Merkle branch.
For those interested in diving deeper, we have more documentation at dev.poktroll.com/protocol/primitives/claim_and_proof_lifecycle
When time permits, there is a lot of related work I’d love to compare this to and seed opportunities to collaborate:
The Compact Certificates of Collective Knowledge from Algorand
STARKs based on Vitalik’s explanation in his post on Binius: highly efficient proofs over binary fields.
The work Eylon Yogev has been doing on probabilistic proofs such as Barriers for Succinct Arguments in the Random Oracle Model.

Finally, the answer to the second question!
It’s simple: do work, sign it, commit it, then prove it.
To prove that this level of incentives works in practice, check out poktscan.com for real data.

I like to use analogies to ground ideas in intuition.

The OSI model is a good place to start when it comes to anything networking-related.
Hopefully something here sticks, but a few of my favorite analogies from the list are:
Uber for RPC requests
Incentivized TCP/IP
Verifiable Counter

The age-old question: is it, or can it be, a rollup?
I wrote about us transitioning to being a rollup last September, but ultimately we decided to simply use the Cosmos SDK. The slide below captures the key details and I plan to write a much longer post on this topic at some point in the future.

I usually end with a few slides on future and related work, but I wanted to focus on the single highest leverage item: Artificial (Augmented?) Intelligence.
The primitive of Relay Mining and decentralized RPC extends to Web3 queries, relayers, and decentralized social (AT protocol, Mastodon, etc), indexing, rollups, but the biggest bang for the buck in today’s market conditions is LLM inference.

A Web3 RPC is just a request, query and response. LLM inference is just a prompt (request), compute (query) and response. It’s the same problem, and we have all the building blocks in place to enable it.
We recently wrote a whitepaper on this topic: Decentralized AI: Permissionless LLM Inference on POKT Network (https://arxiv.org/abs/2405.20450).
Large NVIDIA H100 (i.e. supercomputer) clusters are necessary for training large foundation models or inferences that are very latency-sensitive such as GPT conversations. However, most use cases (CI/CD, cron jobs, reviews, etc…) do not suffer from a difference in 10-second or 20-second response times. At scale, these costs add up and anyone who has spent some time in the MLOps space knows that async workflows can take minutes or hours to complete anyhow.
There is a huge middle market of GPUs and users that can be serviced by enabling LLM inference on the network, reusing the same primitives, ecosystem and infrastructure we have built to provide real value to the end user.
For reference, similar to the web3 infrastructure space, there is a huge industry of LLM API providers: artificialanalysis.ai/leaderboards/providers.

Lastly, Uri Levine (founder of Waze) recently appeared on Lenny Rachitsky’s newsletter and had a key insight: the first and last slight of the presentation is where most of the focus will be. I took his advice and added a call to action at the very end. To my surprise, it worked! I literally had people come up to me after the presentation and tell me about their idle GPUs.
Also, turns out someone out there is doing their phd on Relay Mining and decentralized RPC. If you’re reading this, let’s take this work tot he next level!


