
How a Web2 Company Uses Crypto to Power Open Data APIs
There is a big opportunity to build the "Google home page" for finding and accessing APIS for open data sources and services.

Thank you to Art, Fred & Jake for reviewing and providing feedback on this post!
Question: Does your software use APIs? Where do you find the endpoints? How do you get the specifications? How do you ensure quality? 🤔
tl;dr
There is a big opportunity to build the “Google home page” for finding and accessing open data sources and services.
An open marketplace of APIs does not exist today.
API Discovery and RPC Quality are the two core primitives necessary to enable this.
An API marketplace fills a gap alongside the new HTTP x402 standard, championed by Coinbase, for internet-native network request payments.
My goal with this blog is to give you a sense of how the following graphic fits into today’s internet-native data access landscape. We’re slowly shifting to account for more human-out-of-the-loop workflows, while continuing to accommodate both enterprises and independent developers.
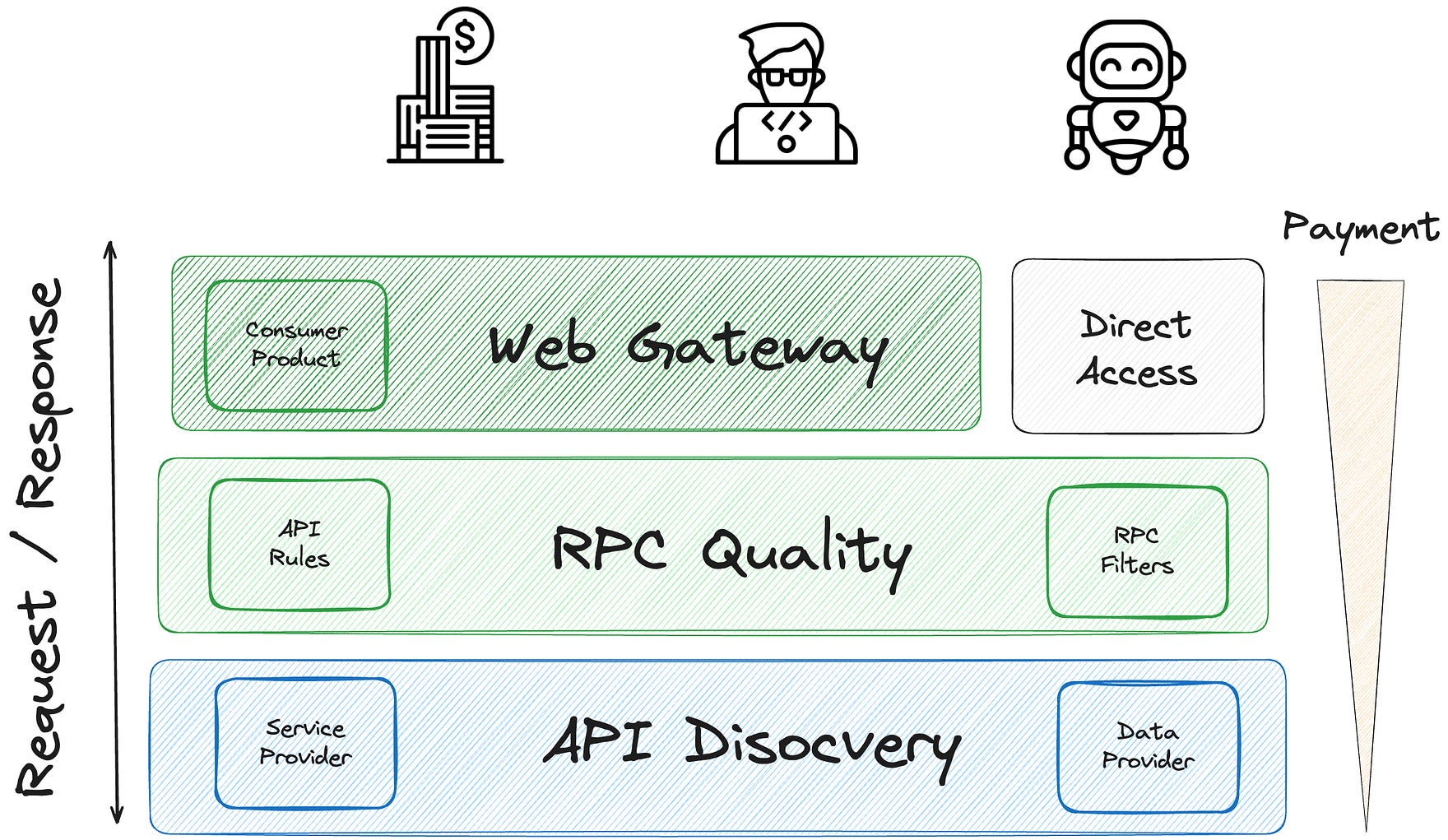
I recently did a 2-minute pitch of Pocket Network, PATH and Grove at the Science of Blockchain Conference.

I received feedback from people at the event, my team watching remotely, my friends, and most importantly, my mom.
I wanted to gather all that feedback in a blog post that really captures how big of a problem (opportunity) everyone is overlooking.
To get started, here are some analogies I found myself using in various conversations at the conference:
Unstoppable Data: kind of makes sense, but feels a bit cringey.
API Directory: Clear but limiting, and makes me sound like a boomer, which there’s nothing wrong with 😏.
Permissionless APIs: Sounds cool, but why does anyone need this?
Decentralized RPC: This might make sense to someone deep in Web3, but raises more questions than it answers.
My goal with this blog is to provide more answers than questions. It’s written in a way that you don’t have to read it until the very end to get value. This allows non-technical individuals to get the gist, while crypto-native engineers can get the details.
Table of Contents
What’s the problem in non-technical terms?
tl;dr Humans need browsers and search engines to find websites. Programs need directories of data providers, along with technical specifications that explain how to access that data.
When humans use the internet, they need a browser and a way to find the right website or link. At first this looked like the Yahoo Directory, then it evolved into search engines like Google, and today it’s increasingly shifting toward chat interfaces like ChatGPT.
When computer programs interact with the internet, they also need a way to find, communicate with, and retrieve the data they need. This usually comes in the form of an endpoint to a data or service provider, accompanied by a technical specification explaining how that data can be accessed. Instead of a computer screen, a mouse, and a keyboard, all that’s required is a server and a reliable internet connection.
Take the weather app as an example: how does it know where to get the data, what format that data comes in, and how to parse it?
This is where internet primitives like APIs and RPCs come in. They’re the forks and knives of accessing and parsing data online.
If you’ve never heard these terms before, that’s fine — just think of this as the core problem we’re solving. If you are familiar, the next section will dive deeper into the API economy.
What’s the problem in technical terms?
tl;dr The internet runs on APIs over RPC. While API specifications and RPC performance are well-studied, API discovery and RPC quality remain under-discussed, and are critical for the coming agent economy.
What is an RPC? A Remote Procedure Call is the medium programs use to communicate over the internet (the transport layer). Think of it as the wire carrying the signals.
What is an API? An Application Programming Interface is the language spoken on top of that wire. It’s like the difference between communicating in Morse code vs. English.
API Discovery: If you’re Gen Z, imagine a YouTube “discover” page, but for APIs. If you’re a Boomer, think Yellow Pages, but for APIs.
In reality, developers usually just ask around, search Google, or prompt ChatGPT. I asked over two dozen engineers how they find APIs, and even in 2025, it’s still an ad hoc process with no consistent standard.
RPC Quality: How can you be sure a provider’s data is reliable, performant, and correct? Service level agreements try to cover this, but in practice customers simply assume it works. When you open Netflix, you expect a stream to play, and your expectation of success is essentially 100%.
We have mature ways of measuring performance (e.g. latency), but no standards for quality (e.g. correctness). Unless you trust WebsiteYouGotDataFrom.com, you can’t be certain the data is right.
The key takeaways:
We have standards for defining API specifications, but no mechanisms for API discovery.
We can measure RPC performance from a trusted provider, but we have no way to guarantee RPC quality from an unknown one.
The next section will dive into the types of data you might want to access and how our solution addresses these gaps. If you already get the gist, feel free to scroll and just enjoy the pictures.
How big is this problem?
tl;dr API discovery and RPC quality are open problems for any software systems. The first iteration of our solution transfers broadly from any open canonical dataset to any open-source stateless service.
To scope the markets we’re tackling, I split them into two categories:
Open Canonical Data Sets: Publicly available data sources that are not user-specific (i.e. tenant-based).
Open Source Stateless Services: Open source services accessible via publicly specified APIs.
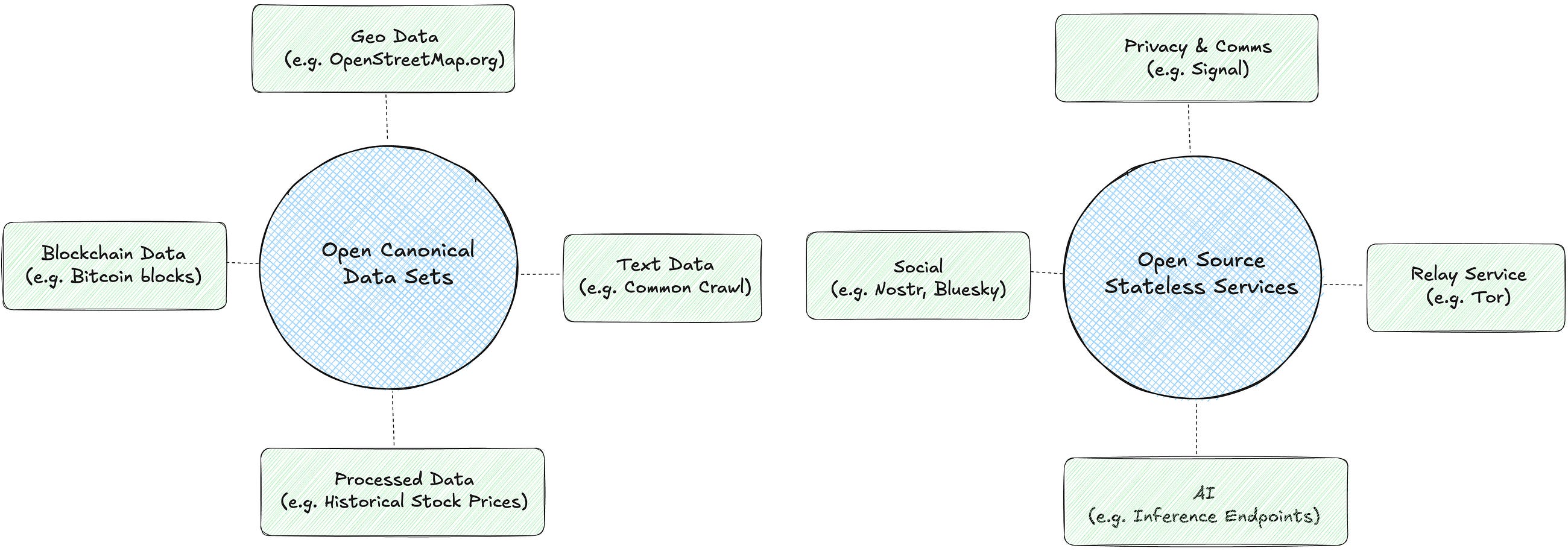
I’ve been asked if this is a data marketplace. If you squint and skip a few steps, it theoretically could be. In practice, we need to focus on being 10x better than anyone else at these two things. Once we get there, a data marketplace is definitely on the horizon.
The more I think about it, the more I realize starting with blockchain data was a bootstrapping coincidence. We could have begun with weather data, but the market wasn’t big enough. Blockchain simply gave us the largest initial opportunity.
Next, we’ll dive into how core crypto primitives like incentives and permissionlessness play a role in solving this problem. These primitives are critical to differentiating a world where you need to go and get someone’s approval to sell something, or just open up a kiosk on the street without any permits. If you provide a high-quality product, you’ll earn what you deserve, and no one cares if you have “an official signoff”.
What is the solution?
tl;dr A public incentivized ledger (Pocket Network) enables API discovery. An open-source SDK (PATH) guarantees enterprise-grade quality. A for-profit product (Grove’s Portal) abstracts it all into a trusted developer experience.
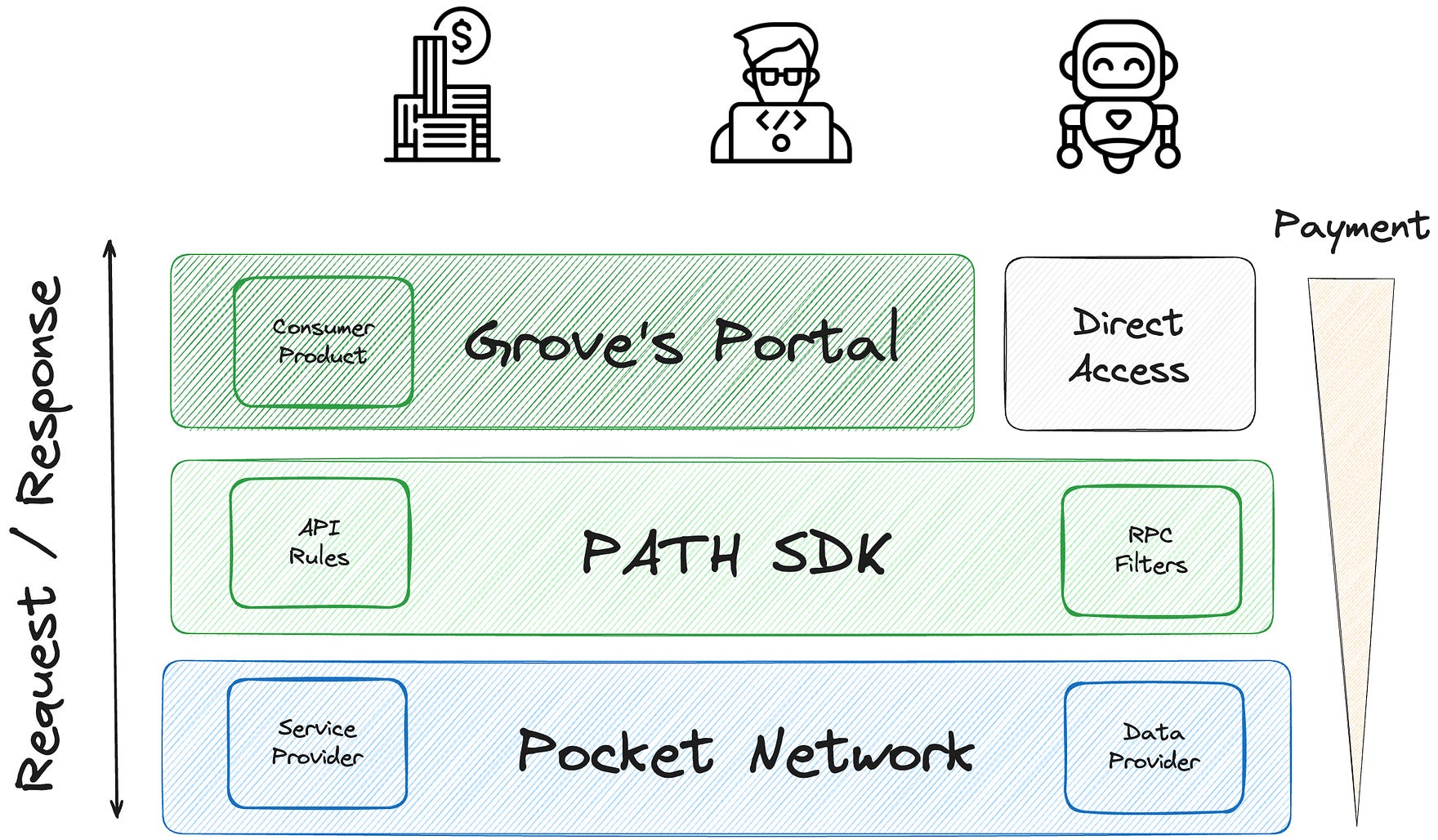
The full solution comes together through three components: Pocket Network, PATH and Grove’s Portal.
Pocket Network is a blockchain with built-in incentives. Anyone can advertise or discover APIs for data sources or services they need. Service owners and service hosts get rewarded based on the verifiable API meter.
💡 Beyond discovery, Pocket Network designed a novel permissionless cryptographic mechanism to meter API usage and settle payments per request. This is where Coinbase’s new HTTP x402 standard for internet-native payments becomes relevant. There are lots of details to dive into which I’ll save for another post.
PATH is an open-source SDK that any internet gateway can use to enforce enterprise-grade quality on top of Pocket Network’s permissionless providers. If providers are inconsistent, low-quality, or adversarial, PATH ensures requests are only routed to high-quality and performant nodes.
💡 It also unlocks a novel use case: existing infrastructure providers can use the network as fallback “insurance” when their own services go down.
Grove operates a consumer-facing portal where developers can instantly get RPC endpoints for any API on Pocket Network. It provides a trusted brand, customer support, and a UI that abstracts away the underlying complexity.
In practice:
Anyone can access Pocket Network directly, but PATH makes it easier.
Anyone can use PATH, but Grove makes it easier.
One of the coolest things? Grove delivers infrastructure quality and performance on par with centralized providers, even though we don’t run the backend service infrastructure ourselves!
Who is our customer?
tl;dr Our customers are enterprises today, independent developers tomorrow, and AI agents in the future.
Enterprises: Major enterprises already trust Grove to provide reliable infrastructure. For example, we are XRPL EVM’s primary RPC provider and are listed on Google’s Web3 Marketplace.
Independent Developers: These are pay-as-you-go users who sign up through portal.grove.city, add a credit card, and start building. They represent the long tail of developers who want fast, reliable access without heavy setup
AI Agents: Though still early, this isn’t hype. AI agents will need access to data. They’ll need to know where to find it, how to access it, and they’ll need guarantees that requests succeed with high quality. And importantly, they’ll pay for it using internet-native money.
That last point deserves its own post…
What is the moat and differentiator?
tl;dr Pocket Network and PATH make it possible for Grove to build a business through the open-core model.
To understand how Grove can become a large, profitable business, it helps to look at the open-core model in practice. Let’s use Supabase as an example.
Supabase is a development platform built on PostgreSQL. Postgres has been around since the late 80s and open source since the late 90s. Hundreds of companies have tried to build businesses on top of it, with varying levels of success. By the 2010s, hyperscalers like AWS, GCP, and Azure were all offering hosted Postgres solutions.
So how did Supabase, founded in 2020, offering “little differentiation”, end up onboarding 3M+ developers and reaching a $2B valuation in under five years? There’s no single answer. For one, it obfuscates the details of how a database works, enabling anyone (non-technical individual or AI agents) to seamlessly spin up a database. Even as a developer, I default to their product because of the superior and simple user experience.
Similarly, just as there was once no obvious answer to “Where can I easily get a hosted instance of Postgres?”, today there’s no obvious answer to “Where can I find a reliable API provider for ___?”
A sustainable API ecosystem can’t be maintained by a single entity, which is why you need Pocket Network. It can’t rely on a single entity for quality either, which is why you need PATH. And most enterprises and developers don’t want to manage gateways themselves, which is how Grove fills the gap.
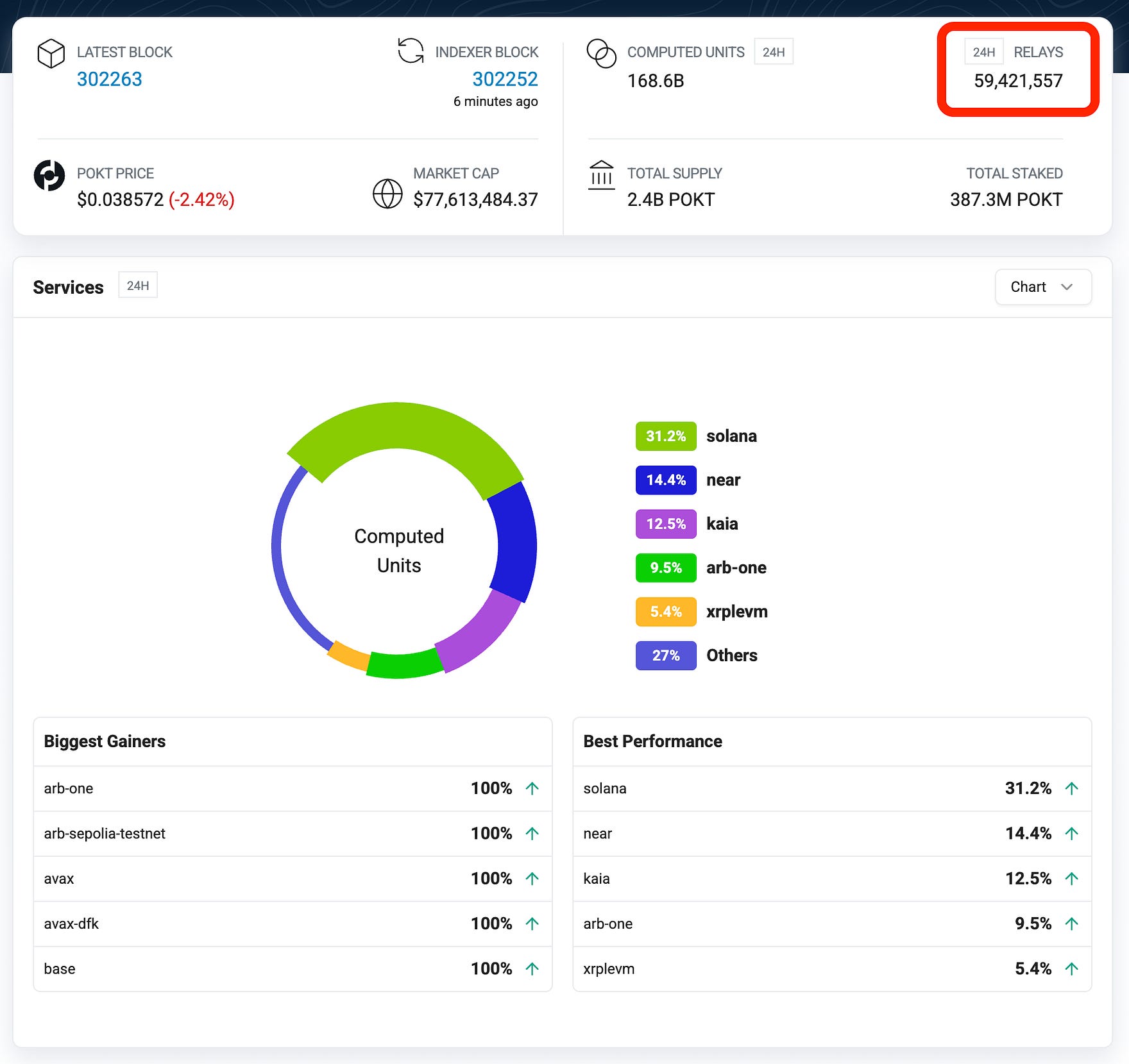
With over a dozen providers and 100+ developers, we’re already handling around 50 million requests per day.
What we’ve built so far has been enough to prove there’s a clear gap in API discovery and RPC quality. We’ve completed the heavy technical foundation and are serving live customers. The next step is to iterate and expand the product.
It’s about supporting more services, adding more providers, onboarding more developers and increasing visibility into what’s happening on the network. In addition, we’ll soon be able to start building out integrations with other networks, protocols and institutions, which is the real unlock.
This is just the beginning! The vision is an open, permissionless fabric of data and services powering the next generation of applications and agents.
Why now?
API Discovery — Enterprises sign deals with close partners. Developers scour the web for a solution matching the tradeoffs they’re willing to make. Agents will iterate in endless circles until they find an API endpoint that matches the specifications they have found for accessing and parsing the data.
RPC Quality — Enterprises rely on service level agreements from close partners. Developers often have half a dozen backups in case one fails. Agents will keep retrying and wasting resources until a request succeeds.
In short, everyone needs a good solution to API Discovery and RPC Quality, yet somehow it’s still missing.
When I asked @kiwicopple (CEO of Supabase) what led to their success, he kept it simple:
There isn’t something uniquely open source about the answer — mostly we a) built something people wanted and b) focused on where the market was moving rather than where it was.
The agentic market presents a large opportunity but is still in its toddler years. In the meantime, we are actively building, iterating and polishing the product for enterprises and developers. Once the world of agents is ready, Grove will be too.
If anything here piqued your interest and you want to reach out, for any reason, Discord is the best way to contact us.
You can try out the product at portal.grove.city, or learn more by visiting grove.city and pocket.network.
Great article! It makes sense to think that as the number of APIs on the web continues to grow, and as robust decentralized infra becomes standard, there is a growing opportunity to establish a completely new way to host and discover APIs.