
No one wants to host their own LLM Model or Blockchain Node

Special thanks to Gabi, Mike, Art, Adz & ChatGPT for the discussion and feedback.
tl;dr
Self-hosting is not a long-term solution since users just want to pay for whatever is cheaper, faster and easier to use.
Infrastructure companies in both AI and Web3 are in a race to the bottom in a commodity market.
Excelling as both a hardware operator and gateway company is increasingly untenable in open-core ecosystems.
Table of Contents
Introduction
One of the allures of open-source ecosystems is the ability to download and run everything locally. In early 2023, when a new model or tool would pop up every week, I’d set everything up on my laptop and feel a sense of instant gratification. You can tinker around, have full control, and it’s “free”!
But the novelty of running everything myself wore off pretty quickly. As a developer building an LLM-enabled application, all I needed was a Reliable, Performant, and Cheap black box that does inference for me. ¹

Similarly, I remember writing my first Ethereum smart contract in 2016 after synching a full node on my laptop. I recall the euphoria of having all the data locally, watching a stream of logs as the node continuously synched with the peer-to-peer network.
This quickly became a bottleneck. My laptop would run out of storage, I’d never be able to turn it off, it would hog most of the CPU, and eventually, it destroyed my battery. Though counter to the ethos of crypto, provisioning my first endpoint on infura.io (an RPC node provider) was a relief.
Similar to the more recent LLM use case, all I needed back then was a Reliable, Performant and Cheap black box where I could execute read requests & broadcast transactions via a simple network call.

Companies that run Blockchain nodes on a user’s behalf are often known as RPC (Remote Procedure Call) Node Providers. At pokt.network, a protocol backed by a decentralized set of node providers, we use the RPC Trilemma to evaluate their tradeoffs.
The biggest observation our team can’t unsee is that the problem faced by AI inference companies today is a mirror image of what we’ve been solving for blockchain nodes for over half a decade.

Web3 vs AI Gateway
When the need for RPC node-running companies came about, it caught the attention of a few different parties. Initially, there were just a handful of major companies in the RPC Node Running business (Infura, Alchemy, QuickNode, Ankr), but that number has exploded as cloud infrastructure became commoditized. I don’t even recognize half the companies on rpclist.com today.
Providing a fast and cheap service became a baseline expectation. The bells and whistles on top of it are the differentiators that independent developers, small teams and enterprise customers are drawn by
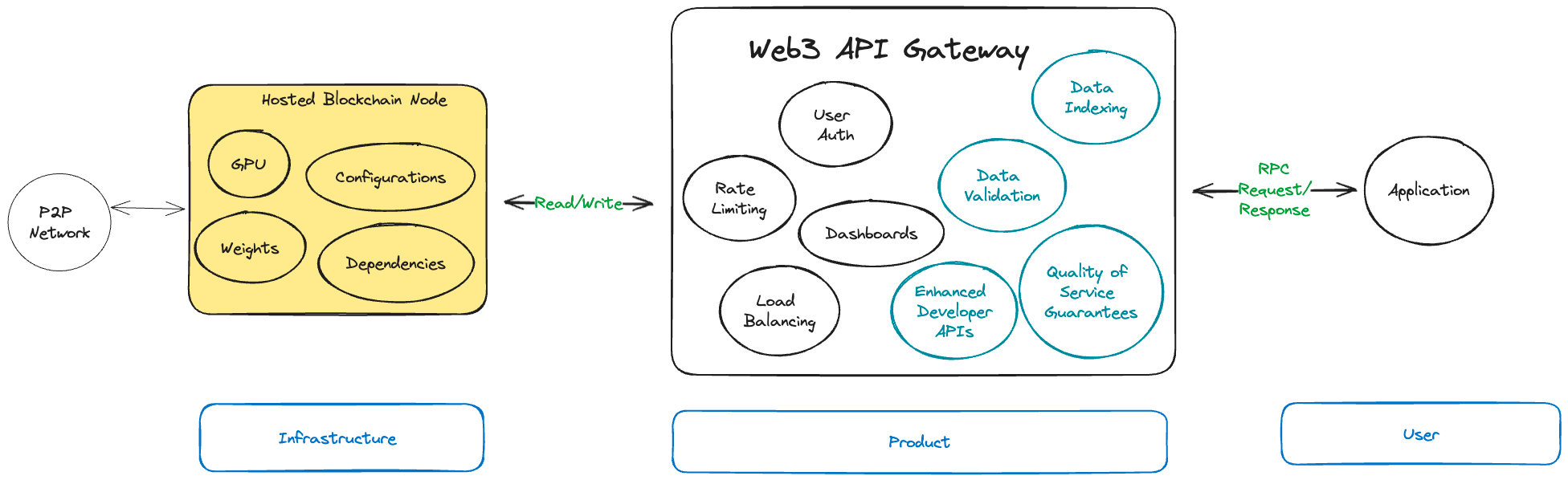
Most conversations related to AI x Crypto, such as Vitalik’s recent post, discuss sci-fi concepts like decentralized agents and their long-term impact on society. However, if we look at where institutional capital is concentrated today, we find a lot of analogs between AI and Web3 companies.

However, before evaluating the tradeoffs across various AI Inference Companies or Blockchain Node Runners, you first need to decide whether self-hosting is a viable option for your use-case.
Should you self-host?
A lot of new blockchains have come out since the emergence of Ethereum. Each one has a targeted use case and comes with its own tradeoffs, but most are non-trivial to maintain on personal laptops anymore. For instance, Solana needs a whopping 512GB of RAM with new blocks coming in every 400ms!
In AI, a lot of new LLMs have come out since ChatGPT took the world by storm. Each one comes with its own tradeoffs and performs differently depending on how it was designed, trained and fine-tuned.
Later in this post, I review some of the hardware requirements to run them effectively, but setting them up to run efficiently is also a non-trivial task. As a result, AI companies have come out of a developer’s need to delegate inference via an API endpoint that guarantees a high quality of service (Reliable), with low latency (Performant), and at a reasonable price (Cheap); octo.ai, together.ai, anyscale.com, fireworks.ai, cohere.com, etc.
Similar to how there were only a handful of these companies in the early crypto days, I expect this number to skyrocket as the tooling and hardware to host an LLM model becomes cheaper and more accessible. This leaves the developer with two options

A non-exhaustive list of tradeoffs a developer needs to take into consideration are:
Cost - Is the price per request worth the services being offered?
Agreement - Do the SLA/SLOs (Service Level Agreements/Objectives) meet needs and requirements?
Trust - Is trusting a 3rd party to act honestly acceptable?
Curiosity - Is giving up the fun and learning that comes with doing everything yourself worth it? If you know, you know 🤓
On the topic of trust, it’s critical to call out that there is a lot of discussion and work around data integrity and verifiability. However, there is no silver bullet solution (that I’m aware of) yet. An AI company may claim to be running Llama 2 with 70B parameters, but how do you know they’re not just running inference on a 7B model behind the scenes? In Web3, Moxie, the founder of Signal, captured this issue very well in a Jan 2022 blog post:
These client APIs are not using anything to verify blockchain state or the authenticity of responses. The results aren’t even signed. An app like Autonomous Art says “hey what’s the output of this view function on this smart contract,” Alchemy or Infura responds with a JSON blob that says “this is the output,” and the app renders it.
These are real problems, and our team at Grove, along with the Pocket community, has many ideas and plans to tackle them in the future. I will leave this discussion to a future post.
For now, I want to walk through what the journey was selecting and running your own LLM entails at a high level.
Selecting an LLM model
If you decide to run your model locally, you’ll quickly find yourself facing The Paradox of Choice. The following list is just a shortlist of the easy questions: ²
Which model should I choose? Llama2, Mixtral, Falcon, etc…
How many parameters do I need? 7B, 13B, 34B, 70B, etc…
Do I need a fine-tuned model? Chat-tuned, Instruct-tuned, Code-tuned, etc…
What kind of hardware do I have access to accelerate inference? Intel CPU, Apple M1/M2/M3, NVIDIA A100/H100, etc…
What framework will I be using for inference? PyTorch, TensorFlow, Llama.cpp, etc…
Should I use a quantized model?
There’s a big chance you’re going to end up on HuggingFace and be presented with a selection like this, trying to figure out which link to click:

Then, you realize it’ll take you more than an hour to download the 150GB file for the high-quality model outlined by NVIDIA:

Later, after struggling to download and configure the best model, you realize you forgot to buy the $40,000 H100 NVIDIA GPU, so the performance will be half decent at best.

You’ll waste time setting up a certain model, only to learn it doesn’t fit your needs. You’ll probably deal with some Python or C++ dependency issues. You’ll learn the GPU on your laptop is not compatible for some reason. The list goes on.
Personally, I always found myself defaulting back to GPT-4 either through ChatGPT or OpenAI’s APIs. Even though GPT-4 has been out for almost a year, it still ranks at the top of ChatBot Arena Leaderboard. A small and simple off-the-shelf model a hobbyist would download and configure themselves doesn’t come close to outperforming it. ³
Who is responsible for optimizing inference time?
As I alluded to above, configuring a machine for optimal inference has a lot of hidden complexity. Chamath Palihapitiya discussed this issue in this 60-second snippet on a recent episode of the All-In Podcast, mentioning how consumer-grade experiences are not practical if we’re waiting 30 seconds for an LLM to respond to a query.
However, not everyone in the AI industry today is working on making things faster, and even when we do have sub-second GPT-4 level inference, it’ll be the amalgamation of different factors.
AI researchers did a lot of the heavy lifting to understand what architecture works (the Transformer), kicking off a major flywheel. Data engineers are experimenting with different data sources, ML engineers are tuning hyperparameters in various ways, Devops engineers are architecting infrastructure to provide maximal performance, and chip designers are innovating on the hardware front. ⁴
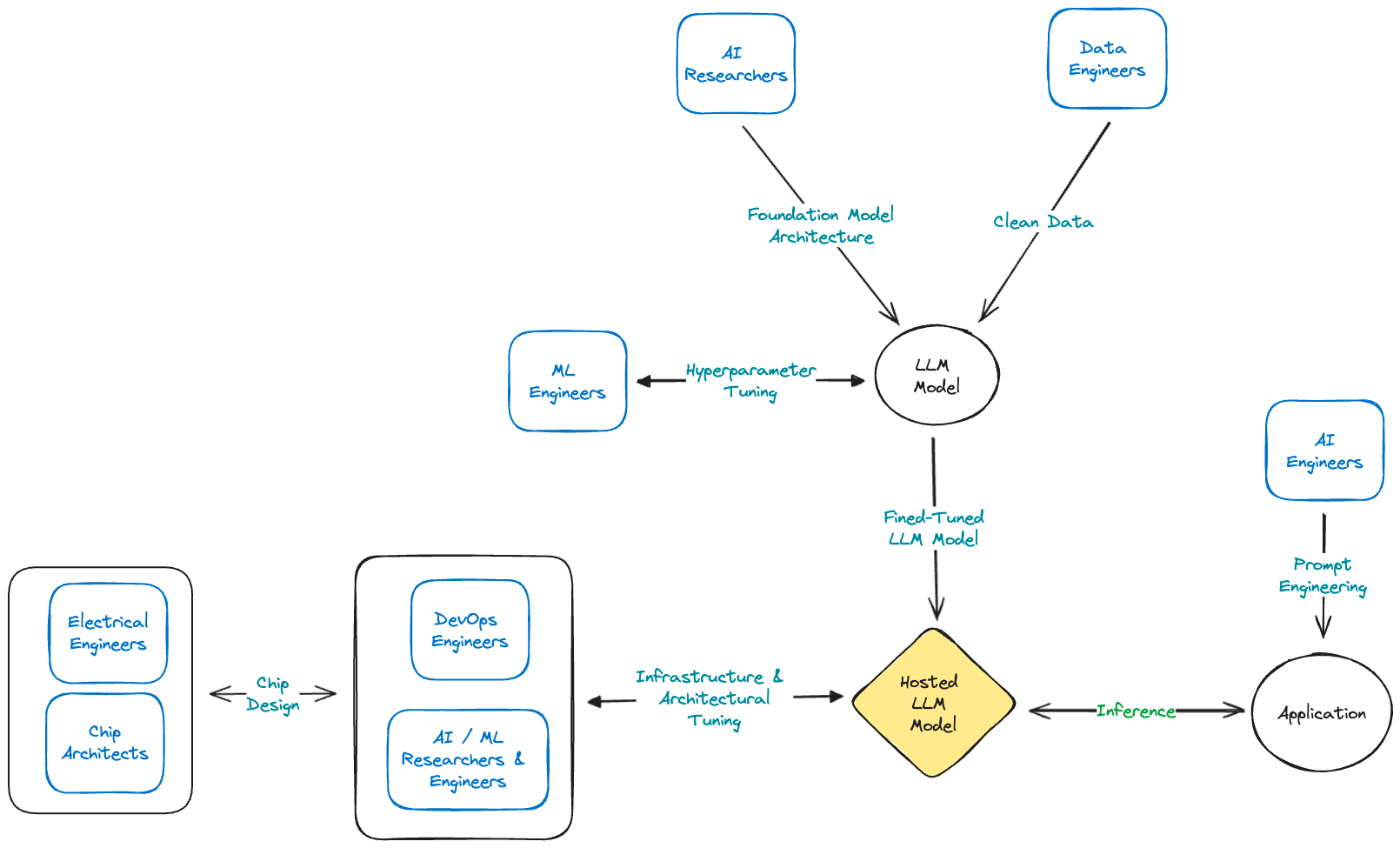
Reducing inference time and power consumption is critical, and I’d bet there is a lot of inefficiency due to the amount of redundant work being done across the industry today. In addition to this redundancy, companies are likely struggling to find a way to differentiate themselves in an increasingly commoditized market.
The AI API Gateway
Aravind, founder of perplexity.ai, mentioned in this 50-second snippet that a major challenge all these companies will face is a lack of moat. ⁵ Looking at octo.ai, together.ai and fireworks.ai, we find a lot of overlap:
Reliability: Scalability and quality-of-service is a top priority.
Performance: Latency is optimized to be as low as possible without sacrificing reliability.
Cost: Price is tuned to be as low as possible without sacrificing quality or performance.



Reliability, Performance and Cost are no longer differentiators, but are imperative prerequisites. Brand, Distribution, Specialization and Marketing are the factors that’ll attract customers and enable AI gateways to come out on top.
Similar to Blockchain Node Runners, a lot of AI API Gateways have started offering bells and whistles on top of their core value proposition to differentiate themselves

So what’s next?
In a recent post by @o_rourke, he made a conservative estimate that at least $1M a day is spent on maintaining LLM inference infrastructure. With more recent information that Anthropic is estimated to generate $850M of ARR and OpenAI at $1.6B, the opportunity might be much bigger.
Companies in AI and Web3 are all splitting their focus around two major verticals:
Infrastructure - Optimizing to reduce the cost and latency of a commoditized service while adhering to specific SLAs & SLOs.
Product - Building value-add differentiators to attract and maintain new users built on top of the infrastructure mentioned above.
Open-source software creates an opportunity for a separation of concerns. Skilled infrastructure operators can focus on managing performant infrastructure. API Gateways can focus on building user-focused experiences leveraging said infrastructure.
This arrangement normally requires a multitude of contracts, deals, negotiations and commitments. Though there is still a lot of work ahead, we have already made great headway at pokt.network to create a free, open and permissionless market where infrastructure providers have a financial incentive to provide a high quality-of-service to Gateways, servicing more than 400M daily relays across more than 50 different blockchains according to poktscan.com. The next upgrade of the protocol is going to enable the same thing for LLMs.
Grove, as the first gateway powered by Pocket Network, has proven over the last several years that it is possible, practical and efficient to maintain more than 4-9s uptime while providing a quality-of-service that meets enterprise customer SLOs. Pocket’s network of decentralized providers enables our team to focus solely on quality of service, tooling, dashboards, and visibility users need to manage their teams. Other product-focused Gateways would then be able to leverage Grove without needing to worry about service maintenance or meeting SLAs. We aim to achieve the same thing for LLM inference in the near future

There is still a lot of work ahead and open-ended problems on different fronts. With that said, I see a ton of opportunity to use Web3 incentives to accelerate the innovation of open-source software in AI and other non-crypto use cases. This will be a win for everyone.
¹ Inference is a term in Machine Learning synonymous with using a model. It is simply the process of getting output text (a prediction) based on input text (a prompt) from a pre-trained model.
² This list is intended to be short and incomplete, focusing only on some of the basic technical aspects. In practice, we’d have to consider pricing, licensing, privacy, etc.
³ There is a lot of nuance on which model one should use for different purposes. My personal opinion is that how a model is trained, and how the RLHF fine-tuning data is filtered, is as individualistic as food preference. Prompt engineering has to do a lot with how one thinks and writes. I have personally been most “aligned” with GPT-4 since day 1.
⁴ The model we’re describing is oversimplified and doesn’t even consider RLHF or other interim steps required in making a model usable. However, OpenAI has a great post that goes into all the details.
⁵ Other companies offer “real AI value add” features on top of basic inference. For example, perplexity.ai challenges Google with a new search paradigm, while mosaicml.com does the work of an ML engineer behind the scenes for you.
> More technically, inference kernels produced incorrect results when used in certain GPU configurations.
This issue from an OpenAI Incident is a clear example of something Suppliers need to worry about that gateways shouldn't need to.
Ref: https://status.openai.com/incidents/ssg8fh7sfyz3